Child Pornography Images Slip Past Filters in AI Training Dataset, Yomiuri Probe Reveals
15:41 JST, March 21, 2024
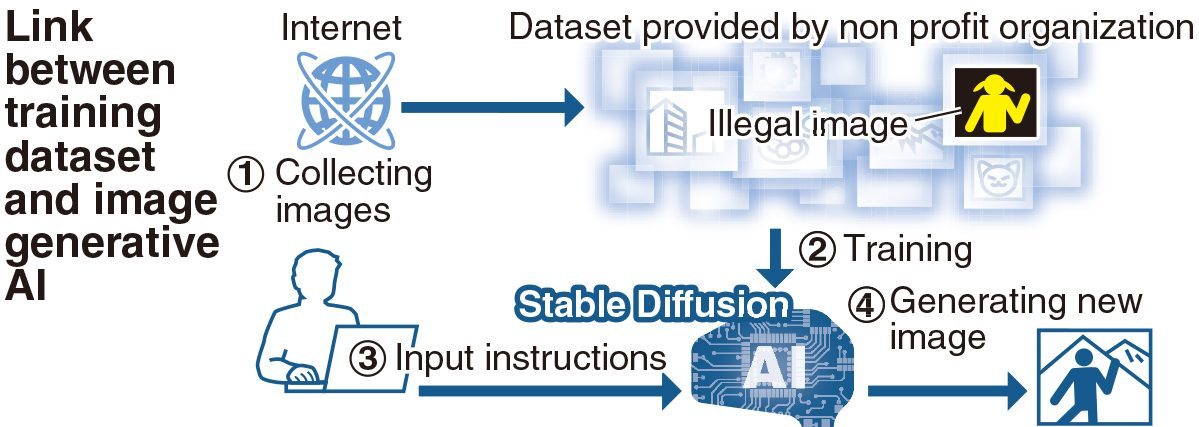
Images of child pornography were found among the vast amount of data that is used to train image generative AI and boost its precision, it has been learned. The materials include at least one from a photography book that was banned by the National Diet Library for “possibly being illegal child pornography.”
A number of other images of naked children were also found in the data, which were believed to have slipped into a dataset while being collected from the internet. There are filters to exclude such images during the process, but it is said to be impossible to catch them all.
Image generation AI is used to produce illustrations or photo-like images from texts. One of the most popular models, Stable Diffusion, uses a training dataset publicly available on the internet.
The Yomiuri Shimbun examined the dataset in December, and found data from the photo book published in 1993 that included a naked girl.
Back then, there were no laws regulating the publication of such books. It was made illegal in 1999 with the enactment of a law covering child prostitution and child pornography, which prohibits the publication of sexual images of children under 18. In 2006, the National Diet Library banned access to the photo book on the grounds that it may constitute child pornography.
Along with the image in that book, the dataset contained a number of others of naked children.
According to Stability AI Ltd, the British startup that developed Stable Diffusion, the dataset used to train its product was provided by a German nonprofit organization that mechanically collected about 5.8 billion images off the internet. That appears to be how explicit materials, including the one from the photo book, made their way into the dataset.
The dataset has a filter to exclude illegal images during use, and Stability AI said it is using this function. However, in February, a company affiliated with Stability AI revealed that it found explicit child images that could not be filtered out.
In December, Stanford University’s Cyber Policy Center announced that it identified 3,226 images in the dataset that it suspected of being what it terms “Child Sexual Abuse Materials,” stating that the presence of such materials likely exerts “influence” on the output of the model.
Stability AI did not respond to inquiries about the possible failure to filter out illegal images.
“It is difficult to completely eliminate illegal images with the current technology,” said Atsuo Kishimoto, director of the Osaka University Research Center on Ethical, Legal and Social Issues. “If child pornography is included in the machine training data, it could be regarded as an infringement of the victim’s human rights.”
Kishimoto added any company developing AI has a social responsibility to implement countermeasures and explain what kind of data is used for the machine learning.




Most Read
Popular articles in the past 24 hours
-

Japanese, Chinese Automakers Roll Out Electric Kei Car Models as ...
-

Heavy Snow Forecast to Hit Northern Japan; Pacific Side May See S...
-

Poképark KANTO Opens, Welcomes Fans from Home and Abroad
-

Exports of Agricultural, Forestry and Fishery Products: Potential...
-

Japan's Ginkakuji Temple to Increase Admission Fees for 1st Time ...
-

Sumo Scene / Sumo Matches Watched by Japan's Emperor for 1st Time...
-

Japan’s Environment Ministry Allows Press to See Inside Building ...
-

Masataka Yoshida Named Final Samurai Japan Selection for March Wo...
Popular articles in the past week
-
Man Infected with Measles May Have Come in Contact with Many Peop...
-

Australian Woman Dies After Mishap on Ski Lift in Nagano Prefectu...
-

Foreign Snowboarder in Serious Condition After Hanging in Midair ...
-

Chinese Embassy in Japan Reiterates Call for Chinese People to Re...
-

Narita Airport, Startup in Japan Demonstrate Machine to Compress ...
-

Toyota Motor Group Firm to Sell Clean Energy Greenhouses for Stra...
-

Beer Yeast Helps Save Labor, Water Use in Growing Rice; Govt Hope...
-

Japan Tourism Agency Calls for Strengthening Measures Against Ove...
Popular articles in the past month
-

Univ. in Japan, Tokyo-Based Startup to Develop Satellite for Disa...
-

JAL, ANA Cancel Flights During 3-day Holiday Weekend due to Blizz...
-

Japan Institute to Use Domestic Commercial Optical Lattice Clock ...
-

China Eyes Rare Earth Foothold in Malaysia to Maintain Dominance,...
-

China Confirmed to Be Operating Drilling Vessel Near Japan-China ...
-
M6.2 Earthquake Hits Japan's Tottori, Shimane Prefectures; No Tsu...
-

Japan, Qatar Ministers Agree on Need for Stable Energy Supplies; ...
-
Man Infected with Measles May Have Come in Contact with Many Peop...
Top Articles in Society
-
JAL, ANA Cancel Flights During 3-day Holiday Weekend due to Blizzard
-
Man Infected with Measles May Have Come in Contact with Many People in Tokyo, Went to Store, Restaurant Around When Symptoms Emerged
-
Australian Woman Dies After Mishap on Ski Lift in Nagano Prefecture
-

Record-Breaking Snow Cripples Public Transport in Hokkaido; 7,000 People Stay Overnight at New Chitose Airport
-
Foreign Snowboarder in Serious Condition After Hanging in Midair from Chairlift in Nagano Prefecture
JN ACCESS RANKING
-
Univ. in Japan, Tokyo-Based Startup to Develop Satellite for Disaster Prevention Measures, Bears
-
JAL, ANA Cancel Flights During 3-day Holiday Weekend due to Blizzard
-
Japan Institute to Use Domestic Commercial Optical Lattice Clock to Set Japan Standard Time
-
China Eyes Rare Earth Foothold in Malaysia to Maintain Dominance, Counter Japan, U.S.
-
Japan, Qatar Ministers Agree on Need for Stable Energy Supplies; Motegi, Qatari Prime Minister Al-Thani Affirm Commitment to Cooperation