9:07 JST, March 8, 2021
How soon cultural differences emerge in children is an issue that many people find fascinating, but it is also more difficult to assess than divergences among adults, as the types of tests administered to the young must necessarily be simple, often ruling out the replication of studies done on more mature participants. Nevertheless, some researchers have managed to design uncomplicated tasks that make it possible to explore these variations even among preschoolers.
I recently came across an ingeniously constructed test related to attention to context, an area in which clear differences have been identified between Japanese and American adults and which I’ve written some past articles about. It’s one thing to note differing results among adults depending on culture, but I was surprised to see evidence that the divergences began very early on.
Megumi Kuwabara, a researcher of cross-cultural differences in cognitive development, and two colleagues investigated young children’s sensitivity to context by comparing how American and Japanese children from 3 years and 4 months to 5 years old completed a set task. It involved seeing whether the children would change the facial expression of a character when the context presumably causing the emotion was removed.
The children were shown a cartoon figure on a card expressing an appropriate emotional response in either a happy or scary context. The happy contexts were a birthday cake, present, ice cream and balloons, and the scary contexts were a roaring lion, ghost, monster and shark. Various American names were used to refer to the cartoon figures shown to the American children, and similarly a range of Japanese names were used in the test with the Japanese children.
The mouths of the cartoon figures in a happy context were formed as an open crescent-shaped smile and those in the scary situation had a wavy, trembling line. Other than the differences in the mouths, the faces were the same. Pilot testing confirmed that children of both cultures recognized these expressions as “happy” and “scared” even in the absence of other facial cues.
Within each cultural group, the children were further divided into two groups. Each child was tested separately. In the first group, the tester told the child involved, “This is (Tiffany). (Tiffany) is (happy)/(scared).” Although the tester specifically mentioned the emotion of the character, no reference was made to the context provoking the emotion. In the other group, the tester simply said, “This is (Tiffany),” without referring to the character’s emotion.
After looking at the card, the children were told to put the card face down in a box. Then they were shown another card with the same character’s body, but this time there was only a circle for the head. In addition, the context had been changed to a neutral one: a chair, notebook paper, cup or spoons. The children were instructed, “Pick (Tiffany’s) head.” They had four choices of heads with different expressions in the mouths: an open crescent-shaped smile, a slighter one-line curving smile, an indeterminate horizontal line, and a wavy, trembling line. The children chose a head, attached it to the cartoon figure with Velcro, and also put the second card face down in the box.
Kuwabara and her colleagues found that the Japanese children were much more likely than their American counterparts to switch the facial expression of the cartoon characters due to the deletion of the emotion-inducing context — but only in the first group, which was specifically told the emotion that character was feeling. After seeing characters in a happy context, 44.8% of the American children chose the same facial expression for the character in the neutral context, but only 31.3% of the Japanese children did.
Both the American children and the Japanese children were less likely to change the character’s facial expression after seeing characters in a scary context, but the difference between the cultural groups was greater. In the scary to neutral shift, 41.7% of the American children changed the facial expression compared to 62.5% of the Japanese children, a disparity of 20.8%.
The researchers further split each cultural group at its median age (4 years, 5 months for the American children; 4 years, 6 months for the Japanese children) into two groups but there was no statistical difference between the face-choosing behavior of the relatively younger and older children in either culture.
Interestingly, though, both the American children and the Japanese children in the second group, which received no information related to the character’s emotion, were random in their mouth-selecting decisions. Less than one-third of the children of each culture chose the same expression as that of the character’s previous expression, but neither did they appear to be making a shift according to any kind of system. The researchers suggest that the noninclusion of information pertaining to the character’s emotional state made it difficult for the children to assess what they should pay attention to in performing the task. The nudge of hearing “happy” or “scared” might lead children to look not only at the characters’ faces but also at what was around them to make them feel this way.
In their discussion of the results, Kuwabara and her colleagues posited another interesting supposition. Not only might Japanese parents encourage their children to pay attention to contexts, but they might additionally promote the display of neutral facial expressions in neutral contexts.
Certainly at least through my teens, I wore my heart on my sleeve, so I was mightily struck by this possibility. That’s a lot of sophisticated processing before even starting elementary school!

Kate Elwood
Elwood is a professor of English at Waseda University’s School of Commerce.





Most Read
Most read in the last 24 hours
-

India’s Arms Indigenization Quest for Self-Reliance / Big Firms, ...
-

Japan Moves Closer to Blocking Illegal Online Casinos as Governme...
-

Shifts Startup Focus to Nurturing Global Winners
-

Princess Aiko Enjoys Imperial Court Music, Dance; Production, Cos...
-

Bibimbap with Spring Vegetables and Asari Clam Miso a Rich Taste ...
-
Mother Supports My Sister Too Much, Gives Her Kids Much More Than...
-

Official App to Help Startups Meet Other Participants
-

Umami History: Kyoto Chef Murata Worked to Share Japan’s Scientif...
Most read in the last 7 days
-
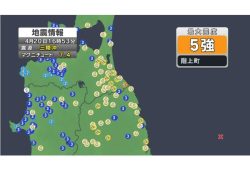
Earthquake Hits Japan's Tohoku Region; 3-meter Tsunami Warning Is...
-

China, South Korea Object to Japanese PM Takaichi's Ritual Offeri...
-

Trump Extends the Ceasefire with Iran but Keeps the Blockade
-

India's Arms Indigenization Quest for Self-Reliance / New Delhi S...
-

¥1,000 Coins to Be Issued to Mark Anniversary of Beginning of Jap...
-

Most Serious Cyberattacks against the UK Now from Russia, Iran an...
-

Trump Opposes United–American Merger, Signals Support for Spirit
-

System Malfunction in Haneda Airport Causes 83 Flight Cancelation...
Most read in the last 30 days
-
Earthquake Hits Japan's Tohoku Region; 3-meter Tsunami Warning Is...
-

Police Find Child's Shoe During Search for Missing Boy in Nantan,...
-

Body Found in Nantan, Kyoto Prefecture, During Search for 11-Year...
-

Cherry Blossoms, Rapeseed Flowers Perform Colorful ‘Duet’ in Niig...
-
China, South Korea Object to Japanese PM Takaichi's Ritual Offeri...
-
Trump Extends the Ceasefire with Iran but Keeps the Blockade
-

Olympic Gold Medal-Winning Figure Skaters Riku-Ryu Announce Retir...
-

Japanese Prime Minister Takaichi Speaks to Pakistani Prime Minist...
Top Articles in Editorial & Columns
-

U.S. Attack on Iran: Even Europe’s Right Wing Has Begun to Distance Itself from Trump
-
U.S. Extends Ceasefire: Lifting Blockades on Strait is Urgent for Negotiations
-

G20 Finance Ministers Meeting: The U.S. Must Fulfill Responsibilities as Forum’s President
-

Promote Support, Respect to Help Prevent Harassment of Athletes
-
Ceasefire in Iran: Make This a Step toward Completely Ending Strikes
JN ACCESS RANKING
-
Earthquake Hits Japan’s Tohoku Region; 3-meter Tsunami Warning Issued (Update 1)
-
Police Find Child’s Shoe During Search for Missing Boy in Nantan, Kyoto Prefecture
-
Body Found in Nantan, Kyoto Prefecture, During Search for 11-Year-Old Boy in Area (Update 1)
-
Cherry Blossoms, Rapeseed Flowers Perform Colorful ‘Duet’ in Niigata
-
China, South Korea Object to Japanese PM Takaichi’s Ritual Offering to Yasukuni Shrine
Most read in the last 24 hours
-
India’s Arms Indigenization Quest for Self-Reliance / Big Firms, ...
-
Japan Moves Closer to Blocking Illegal Online Casinos as Governme...
-
Shifts Startup Focus to Nurturing Global Winners
-
Princess Aiko Enjoys Imperial Court Music, Dance; Production, Cos...
-
Bibimbap with Spring Vegetables and Asari Clam Miso a Rich Taste ...
Most read in the last 7 days
-
Earthquake Hits Japan's Tohoku Region; 3-meter Tsunami Warning Is...
-
China, South Korea Object to Japanese PM Takaichi's Ritual Offeri...
-
Trump Extends the Ceasefire with Iran but Keeps the Blockade
-
India's Arms Indigenization Quest for Self-Reliance / New Delhi S...
-
¥1,000 Coins to Be Issued to Mark Anniversary of Beginning of Jap...
Most read in the last 30 days
-
Earthquake Hits Japan's Tohoku Region; 3-meter Tsunami Warning Is...
-
Police Find Child's Shoe During Search for Missing Boy in Nantan,...
-
Body Found in Nantan, Kyoto Prefecture, During Search for 11-Year...
-
Cherry Blossoms, Rapeseed Flowers Perform Colorful ‘Duet’ in Niig...
-
China, South Korea Object to Japanese PM Takaichi's Ritual Offeri...