To use this site, please disable the ad blocking feature and reload the page.
This website uses cookies to collect information about your visit for purposes such as showing you personalized ads and content, and analyzing our website traffic. By clicking “Accept all,” you will allow the use of these cookies.
Users accessing this site from EEA countries and UK are unable to view this site without your consent. We apologize for any inconvenience caused.
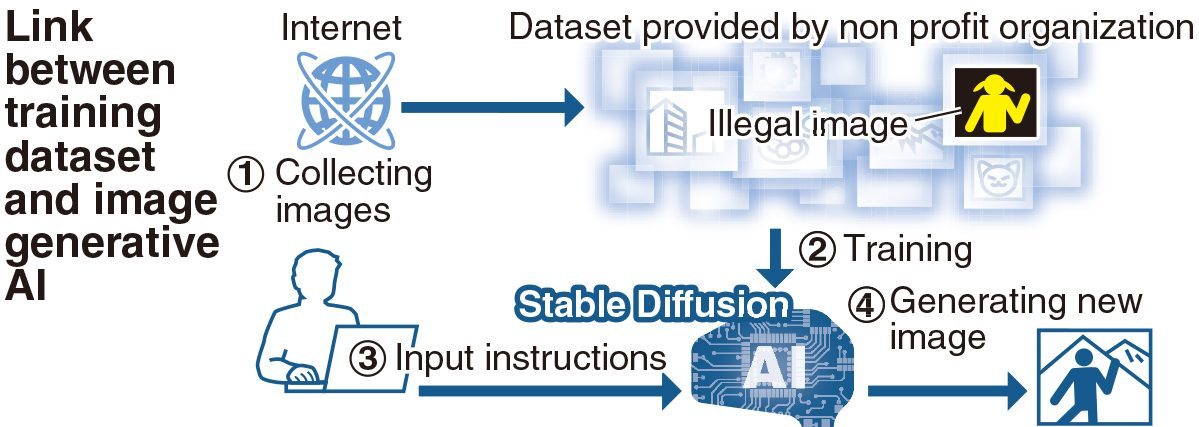
Images of child pornography were found among the vast amount of data that is used to train image generative AI and boost its precision, it has been learned. The materials include at least one from a photography book that was banned by the National Diet Library for “possibly being illegal child pornography.”
A number of other images of naked children were also found in the data, which were believed to have slipped into a dataset while being collected from the internet. There are filters to exclude such images during the process, but it is said to be impossible to catch them all.
Image generation AI is used to produce illustrations or photo-like images from texts. One of the most popular models, Stable Diffusion, uses a training dataset publicly available on the internet.
The Yomiuri Shimbun examined the dataset in December, and found data from the photo book published in 1993 that included a naked girl.
Back then, there were no laws regulating the publication of such books. It was made illegal in 1999 with the enactment of a law covering child prostitution and child pornography, which prohibits the publication of sexual images of children under 18. In 2006, the National Diet Library banned access to the photo book on the grounds that it may constitute child pornography.
Along with the image in that book, the dataset contained a number of others of naked children.
According to Stability AI Ltd, the British startup that developed Stable Diffusion, the dataset used to train its product was provided by a German nonprofit organization that mechanically collected about 5.8 billion images off the internet. That appears to be how explicit materials, including the one from the photo book, made their way into the dataset.
The dataset has a filter to exclude illegal images during use, and Stability AI said it is using this function. However, in February, a company affiliated with Stability AI revealed that it found explicit child images that could not be filtered out.
In December, Stanford University’s Cyber Policy Center announced that it identified 3,226 images in the dataset that it suspected of being what it terms “Child Sexual Abuse Materials,” stating that the presence of such materials likely exerts “influence” on the output of the model.
Stability AI did not respond to inquiries about the possible failure to filter out illegal images.
“It is difficult to completely eliminate illegal images with the current technology,” said Atsuo Kishimoto, director of the Osaka University Research Center on Ethical, Legal and Social Issues. “If child pornography is included in the machine training data, it could be regarded as an infringement of the victim’s human rights.”
Kishimoto added any company developing AI has a social responsibility to implement countermeasures and explain what kind of data is used for the machine learning.